
欠拟合和过拟合
对于之前房价的例子,假设只有一个特征 size。
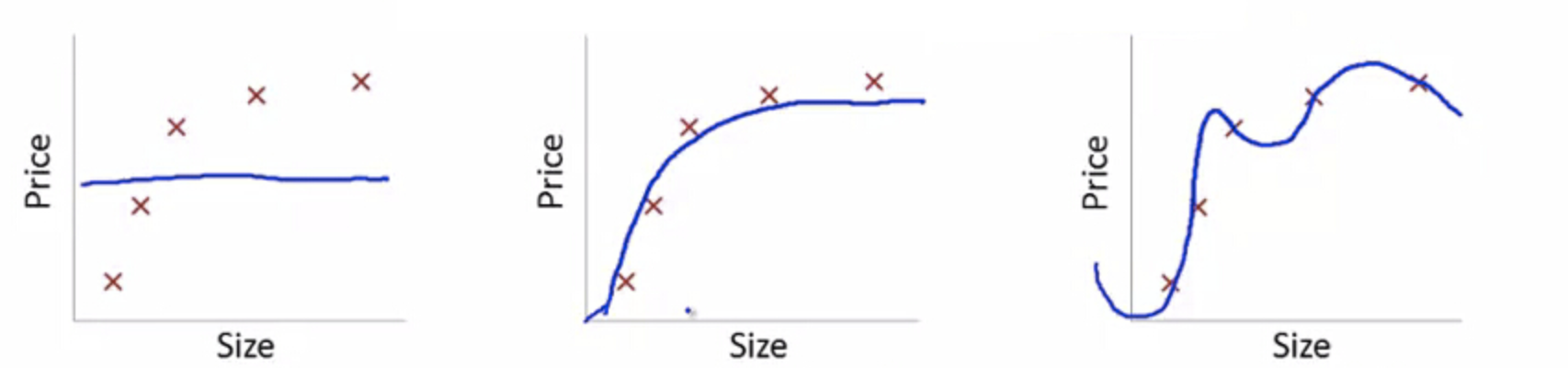
假如,我们只用简单的线性拟合($\theta_0+\theta_1x_1$,$x_1$表示 size),最终拟合结果会变一条直线,就可能产生下图最左边的结果,我们称之为『欠拟合』。
当我们尝试用二次曲线来拟合($\theta_0+\theta_1x_1+\theta_2x_1^2$,可以假设$x_2=x_1^2$,再进行线性拟合),就可能产生中间的结果。
但如果再继续增加曲线的复杂度,对于下图这种五个样本的例子,假如我们用一个五次曲线来拟合它($\theta_0+\theta_1x1+\theta_2x1^2+\cdots+\theta_5x_1^5$)就会精确拟合所有数据,产生右图的结果,我们称之为『过拟合』。
局部加权回归(Locally Weighted Regression)
局部加权回归,是一种特定的非参数学习方法。
什么叫非参数学习方法,首先,简单了解一下『参数化学习方法』(parametric learning algorithm),是一种参数固定的学习方法,如上所示。而『非参数化学习方法』(non-parametric learning algorithm)则不固定参数,参数的个数会随着训练集数量而增长。
我们回顾一下,线性拟合中,我们的目标是找到合适的参数$\theta$,使得最小化$\sum_i(Y^{(i)} - \theta^TX^{(i)})^2$。
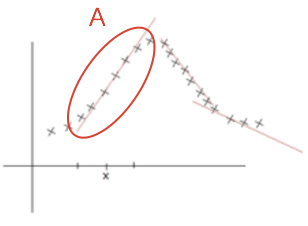
而『局部线性拟合』,则是在某个局部区域 A 进行线性拟合,目标是最小化$\sum_iw^{(i)}(Y^{(i)} - \theta^TX^{(i)})^2$,其中权重,当然,权重公式是可替换的。
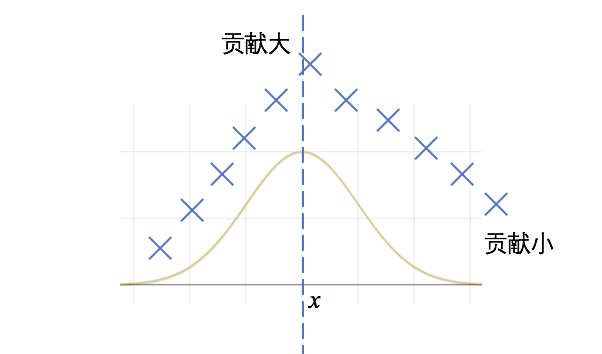
我们观察一下$w^{(i)}$的形状,当数据$x^{(i)}$靠近$x$时,其权重就会较大,那么对目标函数的贡献就会大一些;而数据远离$x$的时候,权重就会较小,贡献就会较小。这样做,目标函数就会更关注$x$附近的数据点,从而达到局部的目的。
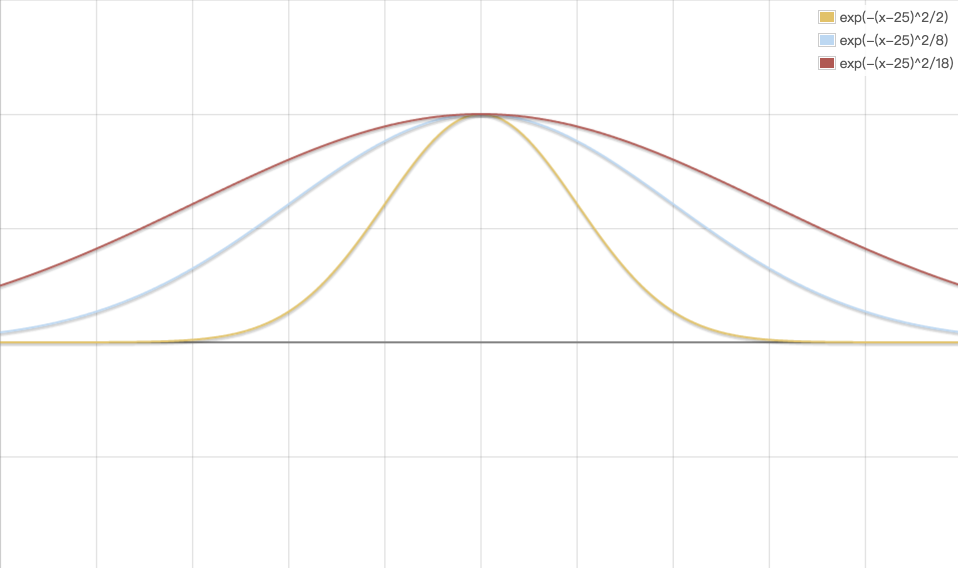
当然,可以调整权重函数,常用的另一个权重函数:(波长函数),$\tau$越大,波形越平缓,局部性越差。
但问题在于,当训练数据较大时,该方法的代价会很高。每要预测一个值,就需要重新进行一次局部线性拟合。